Introduction
Software is everywhere. A lot of it works well all day long. Some of it is terrible. Some of it can kill you.
This article is about critical software, the stuff that really needs to work, and that can have significant consequences if it doesn’t.

There are three trends I have noticed in software organizations:
- The desire to get software into more critical systems (e.g., medical, automotive, transportation, finance and aviation).
- Software organizations are either serious about quality or hopeful. There isn’t much in between.
- For the latter, there is only a vague consideration that current engineering practices should improve when risk increases. It is almost assumed that if software is called “critical,” then it will work, and if it doesn’t, a few more weeks of testing will fix it.
The “just test more” approach works fine until someone is hurt, a contract is lost, or there is serious legal action.
Doing it
Writing software is hard, and writing critical software is harder because there are numerous scenarios that the software has to react to. The increase in risk should cause an increase in better development practices to mitigate the new risk.
The typical (and not so great) approach to improve quality is to:
- Test more and longer.
- Assume that if the system passes the tests then it must work.
- Downplay upfront practices such as requirements, design, good coding practices and peer reviews since they are not coding.
The trouble with the “test more and longer” approach is that if some of the upfront practices were not done, then testing is just a poke in the dark. That is, the testers have no clear picture of what conditions to test for, or when they should be done.
But the tests pass, so it must be OK?
It is wonderful that the (limited) test cases passed (in the limited schedule-crunched time you had for testing). However, let us dig deeper:
- Do the test cases cover all of the likely functions, system scenarios and user scenarios?
- Do the test cases cover every line of code so that you know for sure that some untested conditional loop doesn’t cause a system failure.
- Did anyone look at the code to see that, although it passed the (limited) test cases, the call to “calculate-stuff(input)” will crash the system if the input is zero (when the year is an even number).
- Is the code a huge spaghetti mess that no one actually understands what it does? If a large plate of critical spaghetti code doesn’t make you or your management nervous, you might be dead!
A slightly different approach
In a previous blog I listed some standard quality activities for any type of organization that can be applied selectively to high-risk areas. Those were:
- Peer reviews of requirements, design information and interfaces
- Peer reviews of code and interface definitions
- Peer reviews of test cases and test procedures
- Prototypes and simulation
- Component testing
- Code coverage checks to determine the code has been tested
- Process audits to maintain the adoption of the organization’s best practices
- Integration testing
- Analysis of defect statistics to determine product state and areas for further investigation
- System and acceptance testing using the intended environment, user-oriented requirements and exception conditions
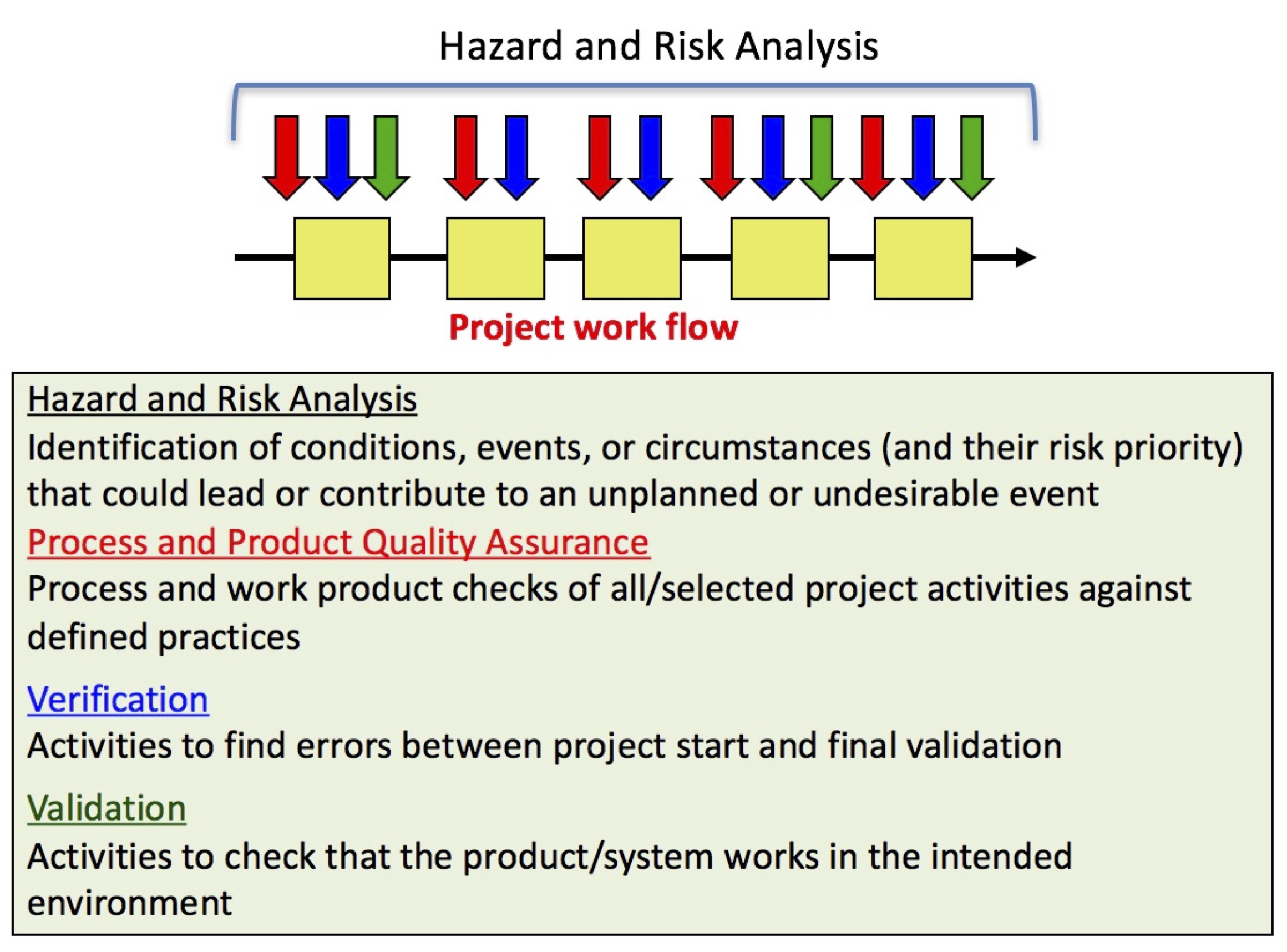
Here are some additional ones if you are in the “This-critical-system-really-must-work” business.
- Definition of requirement quality attributes to define hard quality expectations (e.g., reliability, performance, accuracy, fault tolerance).
- Tracing requirements to test cases to know for sure that the system actually does what it is defined to do.
- Peer review and test of new code, reused code, and “cool code we found on the internet.” Do you really know what you have? If no one has looked, then you don’t know.
- Design for reliability to add characteristics ensuring that defined run periods are met (e.g., a fail-safe recovery vs. a blue screen after 1,000 hours).
- Test coverage analysis to know what has been tested.
- Defect density analysis to understand quality trends and hot spots.
- Hazard and risk analysis of critical functions.
For software organizations that have no design, few requirements, no peer reviews, no traceability and no code coverage analysis, all bets are off.
What you can do
Writing reliable critical code is not easy, and applying the quality practices listed above can be overwhelming. To start, identify between 5 percent and 20 percent of the system to investigate. Here are some example criteria to identify initial system areas to focus on:
- The most critical to the program’s operation
- The most used (and therefore visible) section in the product
- The most costly if defects were to exist
- The most error-prone section based on current defect data
- The least well-known section
- The most frequently changed (and therefore high-risk) section
Not moved yet? Keep reading
Here are two short articles that provide some examples to ponder:
- Appendix F of http://www.system-safety.org/Documents/Software_System_Safety_Handbook.pdf
- http://www.safetyresearch.net/blog/articles/toyota-unintended-acceleration-and-big-bowl-“spaghetti”-code
This article by Neil Potter is on Developing Critical Systems.