The best performing professionals in the IT industry are passionate about learning. Technology is changing rapidly and it is difficult to keep up with the pace of that change. Also, the rapid changes in environment necessitate change in people. Continuous education is imperative to bring the necessary change. Top performers understand the need for consistent learning and this is what enables them to have a successful career in IT industry.
Satya Nadella, in his first email to employees after becoming the CEO at Microsoft, wrote,“Many who know me say I am also defined by my curiosity and thirst for learning. I buy more books than I can finish. I sign up for more online courses than I can complete. I fundamentally believe that if you are not learning new things, you stop doing great and useful things. So family, curiosity and hunger for knowledge all define me.” This powerful statement summarizes the usefulness of acquiring new skills and certifications.
ITIL certification is one such certification. IT professionals who want to advance their career must pursue ITIL certification. Being ITIL certified results inhigher salaries and career advancement. In this article we will take you through various aspects of ITIL certifications to help you better understand the opportunities that lie ahead once you get ITIL certified.
What is ITIL?
A few decades ago, Information Technology was complex and expensive and only skilled professionals understood it. People with great technical expertise used to be part of IT departments and they were the ones who consulted businesses on the IT system and components. Unfortunately, very few of them had a sound understanding of what businesses really needed. This wasn’t the only problem. Large IT organizations were merely managing technology rather than providing services.
The development of the ITIL framework led to the standardization of IT processes. This was the time when IT companies shifted their focus on providing services to their customers rather than just managing technology. ITIL laid a strong emphasis on standardization of processes which helped IT companies in two ways:
- Improving the quality of services
- Reducing the cost of service delivery
It also reduced the dependencies of the advice of the IT professionals in the business and commercial matters and it bridged the gap between technology and business considerably. IT companies became more efficient and effective whenever they adopted ITIL processes. For example
- Implementing incident management helped in resolving incidents quickly at low costs (they needed fewer resources to resolve incidents)
- Introducing capacity management that meant that the IT infrastructure was less expensive and more responsive to business demand
A brief History of ITIL
Before explaining details of ITIL certifications, let us have a look at a brief history of ITIL:
| Year |
Activity |
| 1980s |
CCTA developed a practical framework for “identifying, planning, delivering and supporting IT services to the business.” ITIL was a library of books – Information Technology Infrastructure Library – that discussed specific IT service management (ITSM) best practices, based on recommendations from the CCTA. |
| 1986-96 |
Initial publication of Version 1 of ITIL consisted of 30 plus volumes |
| 1/1/2000 |
ITIL Version 2 had eight sets of books that grouped related process guidelines for the various aspects of IT, namely services, applications, and management. |
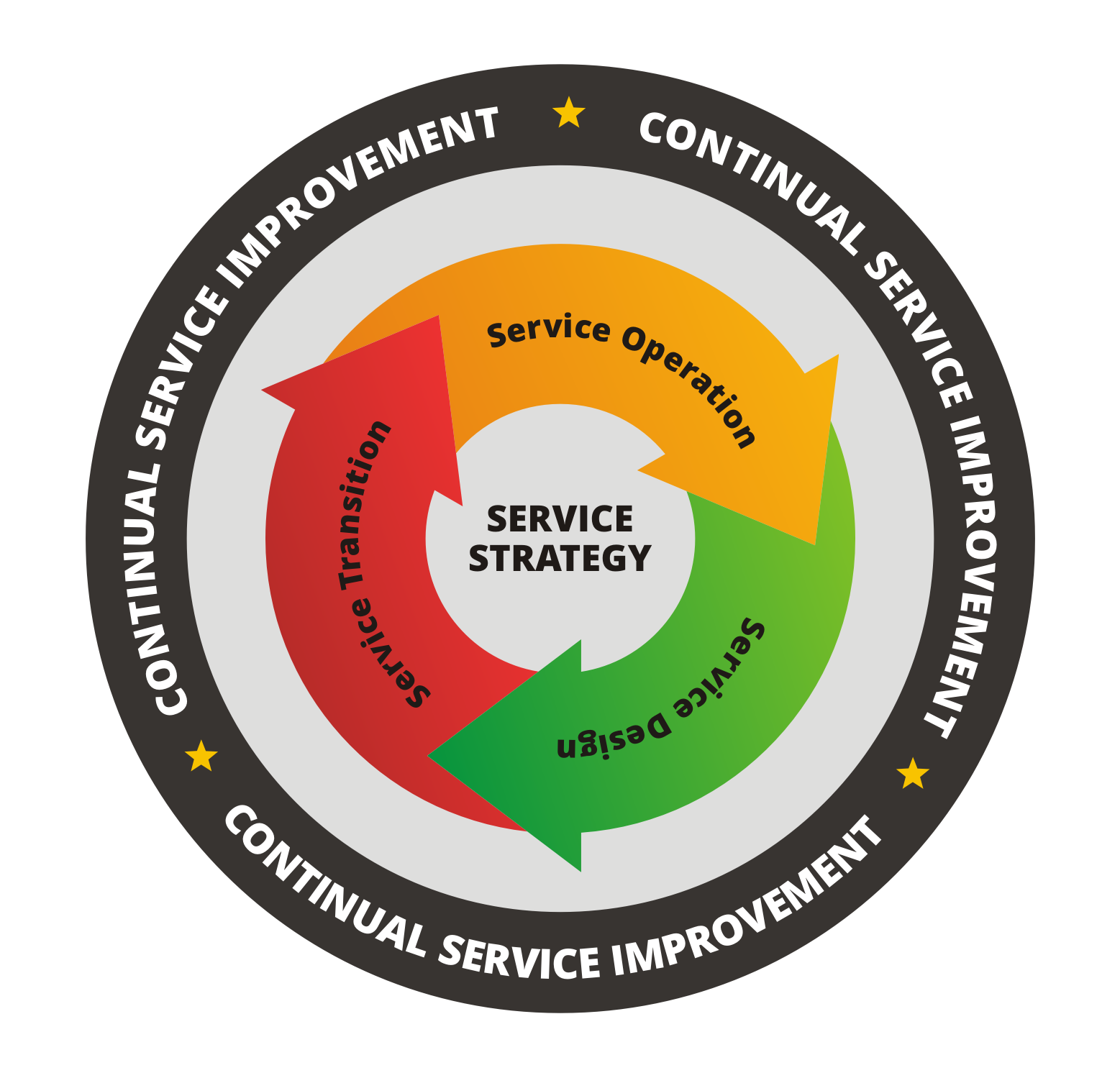
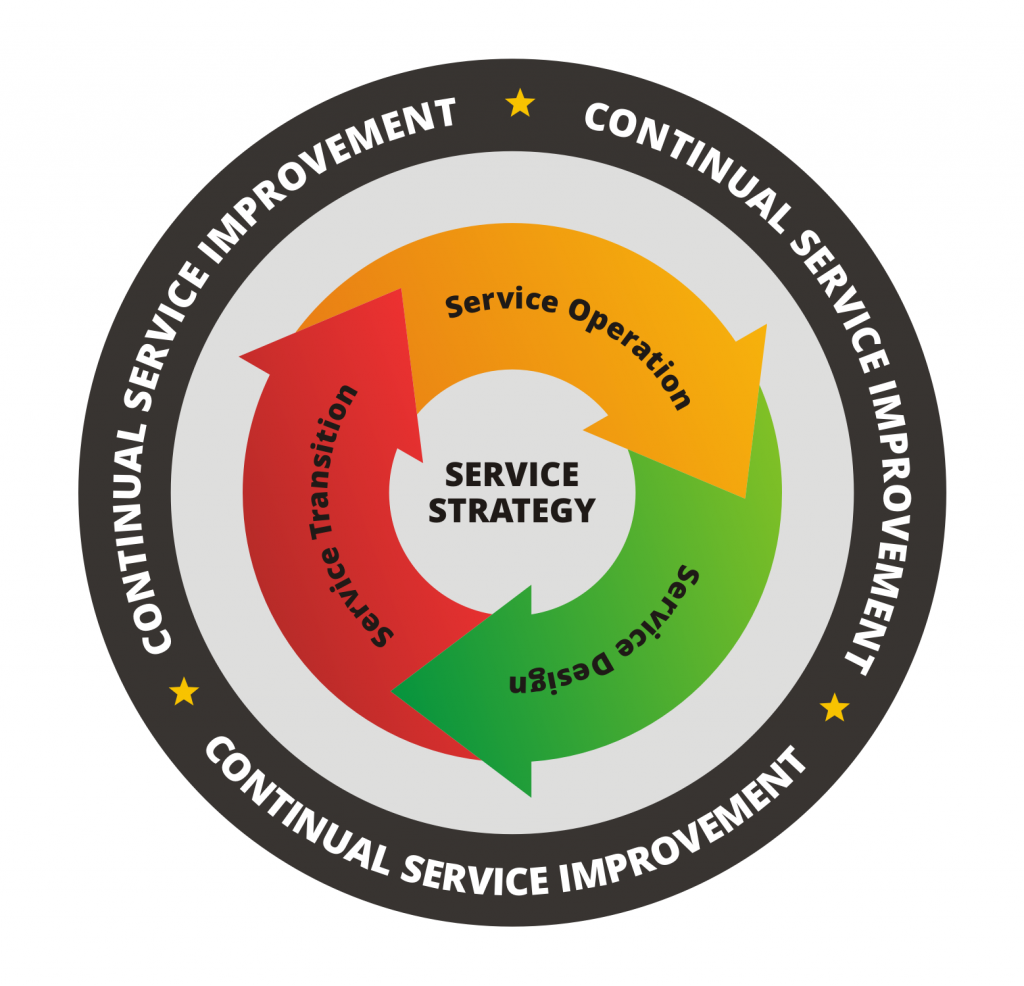
| 2007 |
ITIL Version 3 (ITIL V3 also known as ITIL 2007)consisted of 26 functions and processes that were contained in five core publications namely, Service Strategy, Service Design, Service Transition, Service Operations, and Continual Service Improvement. |
| 2011 |
ITIL 2011 edition defined the formal processes that were not defined earlier and rectified various errors and inconsistencies that had crept in over the years.ITIL 2011 continues to be in use today. |
ITIL Certifications Overview and Credit System
ITIL credit system follows a modular system where you receive credits on completion of each module. The credits earned become qualifying criteria for next module.
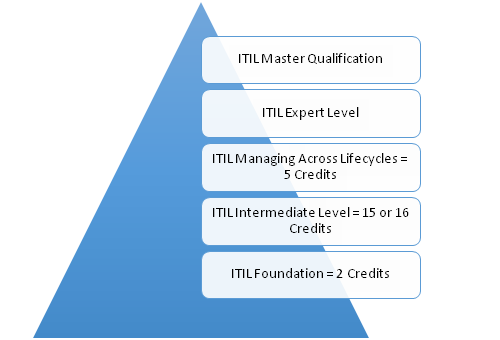
ITIL Foundation – ITIL foundation deals with key concepts, elements and terminology of ITIL services lifecycle management. The first level of ITIL certification with 40 multiple choice question. There is no prerequisite to undertake this certification. It awards 2 credits to successful candidates. No prerequisites are required to take this examination.
ITIL Practitioner – ITIL Practitioner comes after Foundation and is designed to help people implement what they learned in Foundation. ITIL Practitioner training classes are full on workshops that help students implement what they learned in Foundation. It awards 3 credits to successful candidates however it is not a prerequisite to take ITIL Intermediate or other advance level exams.
ITIL Intermediate – The eligibility criteriafor ITILintermediate level requires candidates to have passed ITIL Foundation and complete an accredited training course.Candidates are awarded 15 or 16 credits upon successful completion of ITIL Intermediate exams. There are two elements in intermediate level, Service Lifecycle examinations and Service Capability examinations.
Service Lifecycle examinations includes
- Service Strategy
- Service Design
- Service Transition
- Service Operations
- Continual Service Improvement
Service capability examinations include
- Planning Protection & Optimization
- Release Control & Validation
- Operational Support & Analysis and
- Service Offerings and Agreements
ITIL Managing Across the Lifecycle – You must pass ITIL Foundation and ITIL intermediate level exam and earn a total of 17 credits to be eligible for ITIL Managing Across the Lifecycle (MALC) exam. You will earn5 credits on successful completion of MALC exam.
ITIL Expert Level – You should have earned 22 credits from ITIL Foundation exam, ITIL intermediate level exam and MALC exam to be eligible for ITIL expert level exam.
ITIL Master Qualification – You must be ITIL expert level qualified to appear for ITIL master qualification. To achieve this qualification, you must “explain and justify how you selected and individually applied a range of knowledge, principles, methods and techniques from ITIL and supporting management techniques, to achieve desired business outcomes in one or more practical assignments. (Source: www.exin.com)”
Benefits of ITIL certifications for Individuals
ITIL certifications will definitely boost your career and salary prospects. According to various surveys, ITIL certification is one of the top 20 most sought after certifications (in IT industry) in the world. According to an “Indeed” survey, professionals with ITIL certifications earn 38% higher salary as compared to their non-certified peers. Here is a trend of salaries of ITIL certified individuals over past few years:
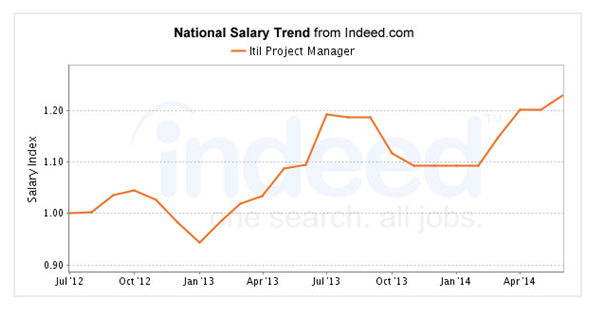
(Source: Indeed.com)
Job Titles For ITIL Professionals
The job titles or designations entirely depend on level of ITIL certifications as well as years of experience in IT industry. After completing ITIL Foundation exam successfully you may enter industry as a Business Analyst or Solution Engineer. At middle and senior level you may become Change Management Manager, Service Delivery Manager, Program Manager – IT, Director – Information Technology, etc.
Advantages of ITIL implementation for Organizations
Most of the major IT companies have implemented ITIL. An ITIL implementation report from Gartner says, “clients have identified improved customer satisfaction with IT services, better communications and information flows between IT staff and customers, and reduced costs in developing procedures and practices within an enterprise”. According to a Forrester survey, more than 80% of businesses thought that “ITIL had improved their organizational productivity and service quality significantly”.
If implemented correctly, organizations can derive the following benefits in the medium to long term
- Improved quality of the services
- Reduction in cost of delivery IT services
- Creating values for their customers and meeting business requirements
- Achieving excellence in whatever they do – Continuously improving the processes
- Improved coordination with clients and partners
- Easy to scale the business
- Focus on SLAs (Service Level Agreements)
Cost of ITIL Certification
Here is a list of pricing for EXIN ITIL Exam cost and passing criteria
| Course |
Pricing (USD) |
No of Questions |
Pass marks |
| ITIL Foundation |
233 |
40 |
65% |
| ITIL Intermediate |
275 |
|
|
| ITIL Managing Across Lifecycle |
275 |
10 |
70% |
| ITIL Practitioner |
319 |
40 based on a scenario |
70% |
You can save some bucks on your ITIL examination fee. Contact us on customerservice@gogotraining.com and we will arrange a coupon code for you.
Cost of ITIL Training Program
The cost of ITIL certification courses differs from institute to institute. It depends on the experience of the instructors, their competencies and track record. While selecting a training institute, you mustn’t focus entirely on the cost. It is necessary that you strike the right balance between the cost and other above mentioned factors. GogoTraining offers an excellent combination when it comes to cost and the experiences and skills of the trainers.
You can check out the cost of training program here: https://gogotraining.com/training/libraries/17/itil/
If you want to know more details or have any queries, just send an email at customerservice@gogotraining.com for current discount and offers on ITIL training programs.
Advantages of our Online ITIL Training Courses
- Instructor Led Training Program
- Experienced Instructors with 20+ years industry experience
- Access to Instructors for support and queries
- Self-paced learning – You can learn at any time as per your convenience
- Cost effective as compared to classroom programs.
You can take advantage of these benefits and much more from the online courses at GogoTraining. We ensure that our students get the necessary support and incubation that will allow them to not just complete the certification courses in a convenient manner but groom them as efficient ITIL professionals with the required competencies and skills.
How to choose right training provider for ITIL Certification?
The first thing is to ensure that you enroll only to an Accredited Training Service Provider and Examination Institute.
There are a number of Accredited Training Organizations (ATOs)those that have been fully accredited by an approved Examination Institute and provide ITIL certification courses, both online and in person.
- Check their track record
- Instructor’s experience
- Course Details
- Pass Percentage
GogoTraining is an Accredited ITIL Training Organization. Accredited by Axelos and EXIN in ITIL Foundation through MALC and will be releasing the ITIL Practitioner course Summer 2016. Course authors have been working in teaching in the field for over 20 years and are considered top in their field. GogoTraining has the necessary accreditation and we have helped numerous ITIL aspirants to realize their potential of becoming successful ITIL professionals.
Still have a query? We are here to help. If you want to know more details, have any questions, or would like to find out about current discount offers on ITIL Training Programs contact customerservice@gogotraining.com.