
Region 1 Discount: Click Here

Region 2 Discount: Click Here

Region 3 Discount: Click Here

Region 3 Discount: Click Here

Region 1 Discount: Click Here
Region 2 Discount: Click Here
Region 3 Discount: Click Here
Region 3 Discount: Click Here

The ITIL 4 Managing Professional certification path is focused on how to run successful IT enabled services, teams and workflows. It was created to help IT Practitioners who work in technology and support digital teams across the business. The path consists of 4 courses, and we are often asked the best order to take the courses so here is some great input by course author Dr. Suzanne Van Hove. We hope you find this helpful and look forward to hearing from you.
In my mind, HVIT should be taken last if only due to the heavy focus on technology. When designing a service, the focus should be on meeting the needs of the consumer and provider. If you already have a great customer focus, then you can jump into HVIT. Just remember it is the hardest and most intense of the four Managing Professional courses with much memorization of tables included.
~Dr. Suzanne Van Hove

Have you ever noticed that the better your Service Desk gets, the more it gets taken for granted?
You’ve risen to every challenge – solved more incidents faster than ever, improved service uptime, built an amazing self-service portal, and you’re even managing service requests and changes – But somehow, you’re being excluded from key decisions and initiatives.
Service Desks who only focus on providing technical support and “break/fix” services, will quickly find their role limited to supporting back-office systems – with little perceived value to the front-line business of their organization.
Engaging with other teams is difficult unless they’re actually resolving an incident. It seems like the better we get at providing support, the more we are put into that box: “Oh those are the tech support people – we only talk to them when something goes wrong”.
Yet, for many organizations, the Service Desk is the most critical interface between IT and other business units. The more we understand about how the business works, the more we can provide proactive, business-focused services that increase the importance and role of the Service Desk.
We know that the business is being transformed by Digital Technology, but how do we become part of that journey? And how do we change our role to stay relevant and valued?
The PeopleCert Accredited ITIL 4 Practitioner: Service Desk Practice Course helps practitioners and managers to explore how to make and keep their organization’s Service Desk relevant and valuable throughout an organization’s digital journey.
In the PeopleCert Accredited ITIL 4 Practitioner: Service Desk Practice Course you will learn how to:
Click Here to learn more about the course.
Click Here to save $100 on the PeopleCert Accredited ITIL 4 Practitioner: Service Desk course and exam package (List Price $599/Your Price $499).
Have a group to train? Contact Us for Group Discounts.
We contacted PeopleCert to find out if individuals who hold the ITIL Master Designation fall under the 3-Year PeopleCert recertification requirement and the answer is YES.
Because ITIL Master is a designation and not a separate exam, it is renewed in the standard way. For example, if a student takes a new course/exam, then all ITIL 4 certificates the student has obtained, including ITIL Master, will be automatically renewed.

On Friday July 28, 2023 PeopleCert, the international ITIL Certification body Accredited GogoTraining’s eLearning ITIL 4 Specialist: Monitor, Support & Fulfil course. This course is taught by award winning ITIL Expert David Cannon helps students achieve their ITIL Practice Manager and ITIL Master designations.
The new Practice Manager Certifications are based on the recently updated ITIL 4 Practice Guides that are filed with useful guidance and many new features that have never been seen in previous versions of ITIL. For the first time ever each ITIL 4 Practice Guide contains definitive capability criteria for each practice that is mapped to the ITIL maturity model that shows how to apply them in your organization.
The new ITIL 4 Specialist: Monitor, Support & Fulfil Certification enables ITIL Practitioners to:
If you or your organization would like to learn more about these great certifications and how they can help you achieve organizational excellence, we are here to help.
Click Here to contact us via email or call 877.546.4446.

When you purchase this package you will receive 1 ITIL 4 Practitioner course & exam package of your choice. This package retails for $595 and is yours this June for only $395 (you save $200). Taking this course & exam recertifies all your ITIL 4 certifications for an additional 3-years.
There are 3 ways to Recertify:
This package is the LOWEST way to recertify at only $395. When you purchase this package in June 2023 you will receive the course of your choice below and:
Choose from one of the ITIL 4 Practitioner Courses courses below:
Please note that this offer cannot be combined with other offers and is valid June 2023. The 5 ITIL Practitioner courses are set to be released by July 30, 2023. When you purchase the pre-release special offer in June you lock in your discount. The exam voucher is valid for 1 year and can be purchased when you make this purchase or when the course is released. The exam voucher includes the AXELOS book in PDF format and the PeopleCert course support materials so if you want to get a jump on your studies, we can order the exam for you right away. If you have any questions Email GogoTraining Customer Service or call us at 877.546.4446.



Attention all ITIL 4 Managing Professionals
There is a clear and easy path for you to achieve the ITIL 4 Master Designation and recertify. PeopleCert has initiated a Recertification program. The program requires students to recertify every 3-years. There is a lot of information we need to share with you so please read to the end where we will share a very special offer with you.
Key Points
How to Recertify
There are 3 ways to recertify. We will discuss them all here and give you the pro’s and con’s.
How Taking A New Course Gets You Recertified
Taking a new course is a great option because PeopleCert has just released the New Practice Manager Certifications and they have 2 GREAT Features:
The New Practice Manager Certification Gets you the ITIL Master Designation
Ok, for those of you that read to this point – thank you. Here is the scoop. ITIL 4 Master requires you to hold the ITIL 4 Managing Professional, Strategic Leader and Practice Manager Designations and you automatically become an ITIL Master.
SPECIAL OFFERS
PeopleCert’s ITIL Recertification Program goes into effect July 1, 2023 and it starts with ITIL 4 Certifications. Earlier Certifications are exempt. The program requires students to recertify every 3 years.
How Do I Know When to Recertify?
What if I Hold Multiple Certifications?
The good news is that you do not need to recertify each certification. When you recertify one of your certifications, all of them automatically update.
How Do I Recertify?
PeopleCert offers 3 ways to recertify.
Which Method of Recertification is Most Cost Effective?
PeopleCert is releasing a new series of ITIL courses under the heading of Practice Manager. These courses are 1-day and the certification exam is the lowest cost of all the exams – only $237. With these courses you can gain a new certification, valuable knowledge and recertify at the lowest possible price.
The MyAxelos Subscription is well priced too, but you have to allocate 60 hours of your time to achieving your CPD’s. When you factor in what your time is worth, this option becomes very expensive. Paying to take the same exam again, seems like the biggest waste of money. The other options are more economical and give you the opportunity to enhance your skills.

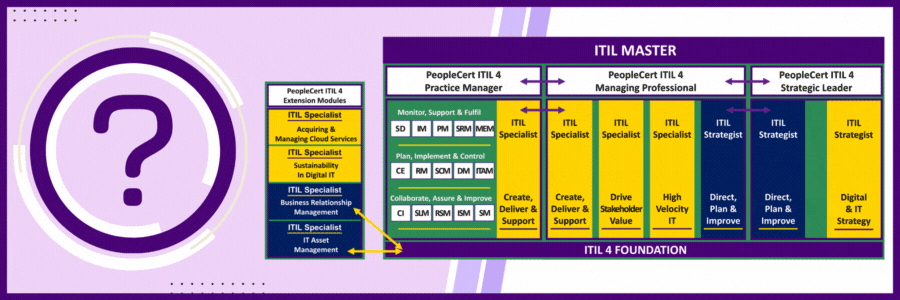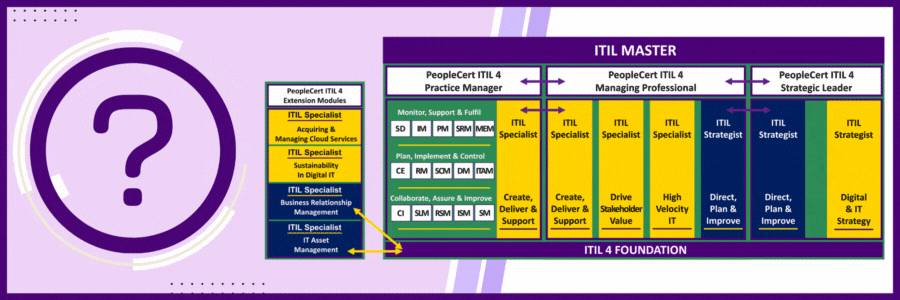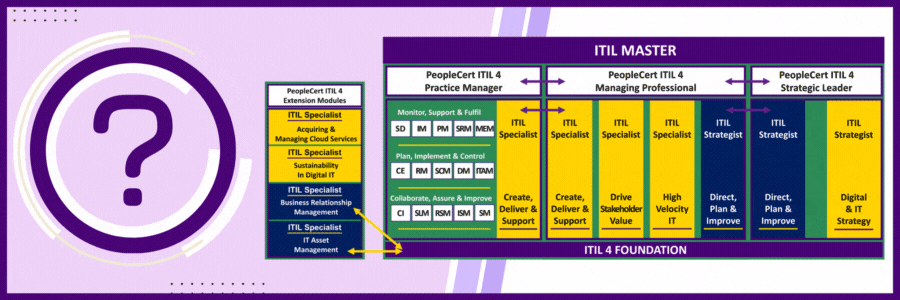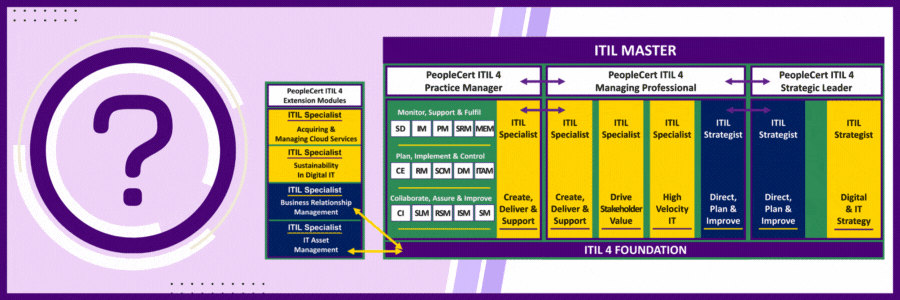
There are 32 ITIL 4 Certifications and 28 Certification Exams. How could this be possible?
The short answer is that students achieve the Practice Manager, Managing Professional, Strategic Leader and ITIL Master designations after they take the certification exams in that category. There is no extra exam to achieve the designation that covers the courses in the respective category.
For example, ITIL 4 Managing Professional consists of 4 courses and 4 exams. When completed students hold the designation for each exam taken PLUS the exam for the category which is ITIL 4 Managing Professional.
Same holds true for ITIL 4 Strategic Leader. When students complete the 2 courses in this category, they hold the designation for each certification and automatically hold the ITIL 4 Strategic Leader Title.
Same for Practice Manager – Only a bit more complicated. With Practice Manager there are 3 categories each with 5 individual courses/certifications and an option to take each course or to take 1 course that is 3-days long and covers the same information.